Exploring Large Reasoning Models: The Emergence of COCONUT
Abstract:
Recent advancements in AI have led to the development of large reasoning models (LRMs) that transcend traditional reasoning methodologies. The introduction of the Chain of Continuous Thought (COCONUT) represents a pivotal shift from discrete token-based reasoning to continuous latent space reasoning. Despite the innovation of models like COCONUT, the foundation laid by naive CoT in existing closed models cannot be overlooked. These models have inherently integrated basic step-by-step reasoning processes. This integration represented a preliminary yet crucial step towards more complex reasoning capabilities. By building upon these basic capabilities, COCONUT and similar models enhance the depth and breadth of AI reasoning. This blog explores research papers explaining the implications of this shift, emphasizing the advantages of latent space for planning, the importance of rewarding learning processes, and the inherent integration of naïve Chain of Thought (CoT) in existing models.

Introduction:
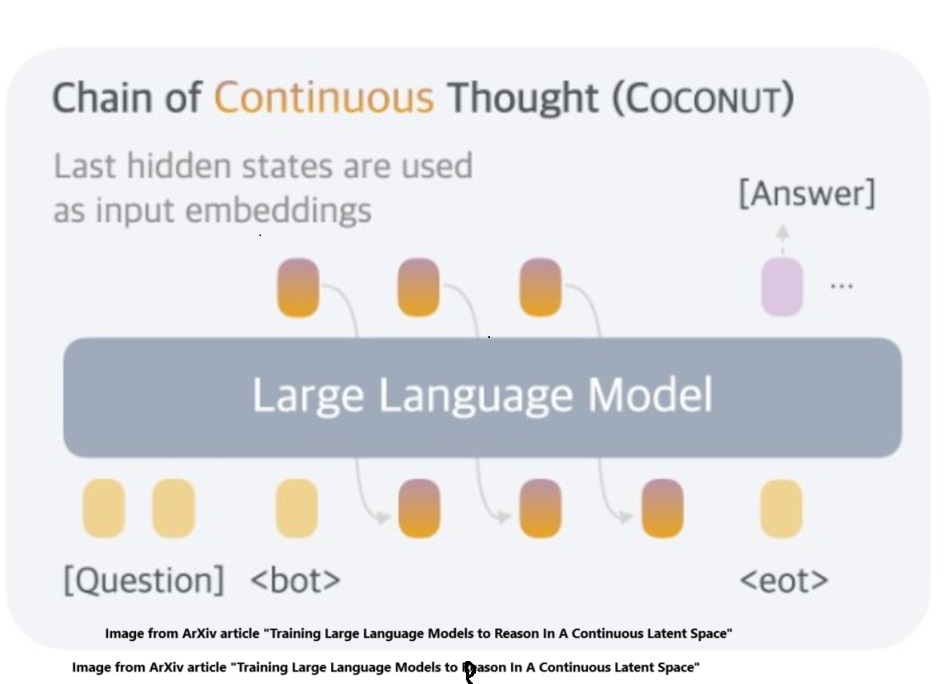
This blog provides an overview of a paper published by Meta and UC San Diego Training Large Language Models to Reason in a Continuous Latent Space. The authors proposed a novel approach for reasoning in a continuous latent space rather than traditional discrete language tokens. This allows the model to consider multiple reasoning paths simultaneously, potentially offering a more dynamic and flexible way of solving problems. The very recent development of large reasoning models (LRMs) marks a significant advance in artificial intelligence, shifting from basic predictive models to systems capable of intricate reasoning and decision-making. These models, including the Chain of Continuous Thought (COCONUT), are a significant advance toward mimicking human-like cognitive processes, allowing machines to handle complex, multi-layered reasoning tasks effectively. Key features are: 1) Uses the last hidden state of the LLM as a continuous input for the next reasoning step, bypassing the traditional token generation. 2) Enhances the model’s ability to backtrack and reconsider decisions, simulating a breadth-first search (BFS) approach in reasoning tasks. 3) Demonstrated to outperform traditional CoT (Chain-of-Thought) in tasks requiring significant backtracking. On September 12, 2024 OpenAI announced the large reasoning model OpenAI o1 Learning To Reason With LLMs. The OpenAI model is proprietary and we do not have insight into the engineering for this model. There was also significant fanfare accompanying the release of the open source DeepSeek-R1 LRM DeepSeek-R1: Incentivizing Reasoning Capability in LLMs Via Reinforcement Learning , however, DeepSeek R-1 approaches the problem from fundamentally different angles than COCONUT and the DeepSeek-R1 model will be discussed in a future blog post. This essay delves into the nuances of COCONUT, discusses the superiority of latent space for planning, and highlights the benefits of focusing on rewarding learning processes over outcomes.
The Rise Of Chain Of Continuous Thought (COCONUT):
Traditional LLMs, like GPT models, have employed CoT, within the constrained framework of language tokens, generating reasoning steps in natural language. Latent space reasoning offers a more flexible approach compared to the sequential nature of language-based CoT. Studies suggest that reasoning in humans often occurs outside the language framework, in what could be referred to as latent spaces—unseen mental models not bound by language. COCONUT innovates by utilizing these latent spaces, allowing the AI to explore multiple reasoning pathways (breadth first searches – BFS) simultaneously without the constraints of language, leading to more efficient and diverse problem-solving strategies and avoiding premature conclusions as the model is not prematurely locked into a single reasoning path.
Advantages of Latent Space for Planning:
Latent space offers a more dynamic arena for AI reasoning, especially beneficial for planning and complex problem-solving. Unlike traditional CoT, which linearly processes through predefined language tokens, reasoning in latent space can simultaneously consider multiple outcomes or steps. This capability is particularly useful in tasks requiring iterative and extensive planning, where multiple potential strategies must be evaluated and optimized in real time.
Process vs. Outcome in AI Training:
The shift towards rewarding learning processes, or “process supervision,” rather than just outcomes, underscores a deeper engagement with the reasoning steps themselves. Process supervision, which rewards each step of the reasoning process, aligns closely with how humans learn and think, enhancing the model’s ability to generate human-endorsed reasoning chains. This method not only improves performance but also aligns AI behaviors more closely with human thinking patterns. The shift towards rewarding learning processes, or “process supervision,” rather than just outcomes, underscores a deeper engagement with the reasoning steps themselves. This approach aligns AI behaviors more closely with desired outcomes and human values, as it encourages models to develop robust reasoning paths that are transparent and justifiable, rather than merely focusing on the end result. This method has shown significant benefits in complex problem-solving, particularly in mathematical reasoning.
Test-Time vs. Training-Time Computing:
In AI development, a distinction is made between test-time compute and training-time compute. Test-time compute refers to the computational resources devoted to “thinking” or processing during the model’s application phase, while training-time compute relates to the “learning” phase where models are trained via methods like Reinforcement Learning from Human Feedback (RLHF). Optimizing test-time computation can significantly enhance an LLM’s decision-making capabilities, particularly under complex conditions where extended reasoning is beneficial. The paper at this link Scaling LLM Test-Time Compute Optimally Can Be More Effective Than Scaling Model Parameters discusses how scaling LLM test-time compute optimally can be more effective than scaling model parameters.
Conclusion:
By transitioning to latent space reasoning and emphasizing process-oriented training, future models will likely exhibit even greater cognitive flexibility and decision-making performance. By leveraging latent spaces for flexible, multi-pathway reasoning and focusing on the learning process itself, these models are not only improving in performance but are also becoming more aligned with how humans think and solve problems. The integration of nuanced reasoning mechanisms and the optimization of computational resources during both test-time and training phases will be pivotal in realizing the full potential of AI reasoning capabilities. The evolution from naive CoT to sophisticated frameworks like COCONUT represents a leap forward in the quest to mirror human cognitive processes within AI systems. As this technology continues to evolve, it promises to unlock new realms of possibilities in AI applications, making AI systems more versatile, efficient, and intuitive in handling real-world tasks.
Impact Statement:
As we stand on the brink of transformative advancements in AI reasoning, it is imperative for businesses to integrate sophisticated AI solutions like those offered by Acuitize AI. We leverages SOTA models to drive strategic decision-making and innovation, offering clients a competitive edge in rapidly evolving markets. Acuitize AI not only equips businesses with leading-edge technology but also ensures they are prepared for the future dynamics of AI integration.
